Robust Word Recognition
Zhao
(Leo) Cheng, Benjamin Walker
Summary
This article proposes the objective, methodology and
discussions in the area of word recognition for completing the term project.
Objective
This project is to build word recognition software which
processes words of varying quality. The word recognition problem can be modeled
as a classification process, recognizing the word by comparing each character
with a trained classifier. This is a very good problem which builds machine
learning skills through hands-on experience in supervised/unsupervised
learning, and some other feature extracting techniques used in character
classification. Similar projects (Spring 2012) in optical word and handwritten
character recognition have shown satisfying performance in achieving high
accuracy with high quality testing data [1, 2]. This project will apply
different algorithms in feature extraction and classification, and train these
algorithms with a more challenging dataset.
In recent decades great progress has been made in character
recognition. There are many commercialized Optical Character Recognition (OCR)
and hand writing recognition packages which provide accurate and high speed
results on good quality input. However, these packages do not work well on
poorly written or low quality documents. Human beings do this type of work very
well based on two factors, 1) exceptional capability to separate the character
with its complex background 2) a preliminary knowledge in understanding the
words make it possible to predict the word with partial or incomplete
information. In this project, we plan to explore some techniques inspired by
human capability to improve the accuracy of word recognition algorithms.
Methodology
The process of word recognition has been partitioned into
five tasks, which include image preprocessing, word segmentation, feature
extraction/classifier training, classifier design, and performance assessment.
In the phase of image preprocessing, an unsurprised clustering algorithm may be
used to separate the word from its background. In order to segment the words
into individual characters, a region connection algorithm will be implemented.
We are planning to try multiple classification techniques, including decision
tree, k-nearest neighbor (KNN), Support Vector Machine (SVM) and Artificial
Neural network (ANN). Finally, the 10-folder cross validation technique will be
applied on training dataset to select the best model, and the performance will
be assessed by validation of the test dataset.
Resource
This project requires two
persons with adequate knowledge of Matlab coding and machine learning
techniques.
The training data and test
data will be obtained from [4]. Each dataset
is provided as a zip file, and contains a set of JPEG images of single words
and an XML tag file. In the ICDAR 2003 dataset, the training dataset contains
labeled 1157 words and the testing dataset is has 1111 words [3]. More data
set with similar format can be obtained from [5-7].
Timeline
The project has been
partitioned into five tasks, each of which is evaluated and assigned,
|
Tasks |
Content |
Workload (week) |
|
Image Preprocessing |
Read data into image matrices from image files Sharpen the image when necessary Separate the word from its background by checking color
histogram |
0.5 |
|
Word Segmentation |
Segment
the words based on region connection Cut
the image into characters |
0.5 |
|
Feature Extraction
& Classifier Training |
Apply a feature extraction technique to train a classifier Learn algorithms with the following classifiers |
1.5 |
|
Classifier Design |
Decision
Tree k-nearest
Neighbor (KNN) Support
Vector Machine (SVM) Artificial
Neural Network (ANN) |
2
(0.5x4) |
|
Performance Assessment |
k-fold cross validation |
0.5 |
|
Documentation &
Presentation |
Milestone
report, Final report Presentation |
1 |
We are expecting to finish the first three tasks by
milestone deadline. In the milestone report, a detailed report on techniques of
image preprocessing, word segmentation and feature extraction will be
presented. We will also test the word recognition and get some results.
Discussion
Figure 1 shows the ambiguity in the letter recognition
problem. If we look from the top-down direction of the left five words, a
sequence of letters (A, B, C) will come into human’s mind. However, it will be
a set of numbers (12, 13, 14) if we look from left to the right. Recognition is
a very hard problem, and trying to do it without considering the context might
result in a classification disaster. To figure this out, we might need a
dictionary or to build a dictionary by some kind of learning techniques. Once we
have the context, the classification rate might improve dramatically. By
checking the bottom right word in Figure 1, a classifier would get the result
“CQDE”, however this makes no sense for human beings.
The most possible reason is the written error of the letter “O”. An
auto-correction may be made with the context to help the machine understanding
(recognizing) words instead of isolated characters.
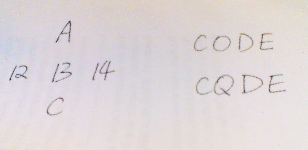
Figure 1 Word Recognition Example
References
[1] Jonathan Connell and Vijay Kothari, “Handwritten
Character Recognition”, CS 74/174 - Spring 2012,
final report of term project
[2] Yuxi Zhang, “Optical
Word Recognition”, CS 74/174 - Spring 2012, final
report of term project
[3] Shahab, Asif;
Shafait, Faisal; Dengel,
Andreas; , "ICDAR 2011 Robust Reading Competition
Challenge 2: Reading Text in Scene Images," International Conference on
Document Analysis and Recognition (ICDAR), 2011 , pp.1491-1496, 18-21 Sept.
2011
[4] ICDAR 2003 Competitions website,
http://algoval.essex.ac.uk/icdar/
[5] ICDAR 2005 Competitions website,
http://algoval.essex.ac.uk:8080/icdar2005/
[6] ICDAR 2011 Competitions website,
http://www.cvc.uab.es/icdar2011competition/
[7]
Letter Recognition Dataset, visited
on 1/22/2013, http://archive.ics.uci.edu/ml/datasets/Letter+Recognition.
Last updated on 1/22/2013